The validator’s guide to understanding and preventing the two most costly mistakes in the Cosmos ecosystem
What Is Slashing?
Slashing is the protocol-level punishment for validator misbehavior. When a validator violates the rules of consensus, a percentage of their staked ATOM — and the stake of every delegator bonded to them — is permanently burned. Gone. Not jailed, not frozen. Burned.
It is the most severe consequence a validator can face, and unlike jailing (which is recoverable), slashing is irreversible.
The Cosmos SDK implements slashing through the x/slashing module, which monitors validator behavior and enforces two categories of infractions: downtime and double signing. These are not equal. One is a warning. The other is a career-ending event if you're not careful.
Understanding slashing isn’t optional for anyone running production validator infrastructure. It’s foundational.
The Two Types of Slashing Infractions
1. Downtime (Liveness Fault)
What it is: Your validator fails to sign a minimum number of blocks within a sliding window.
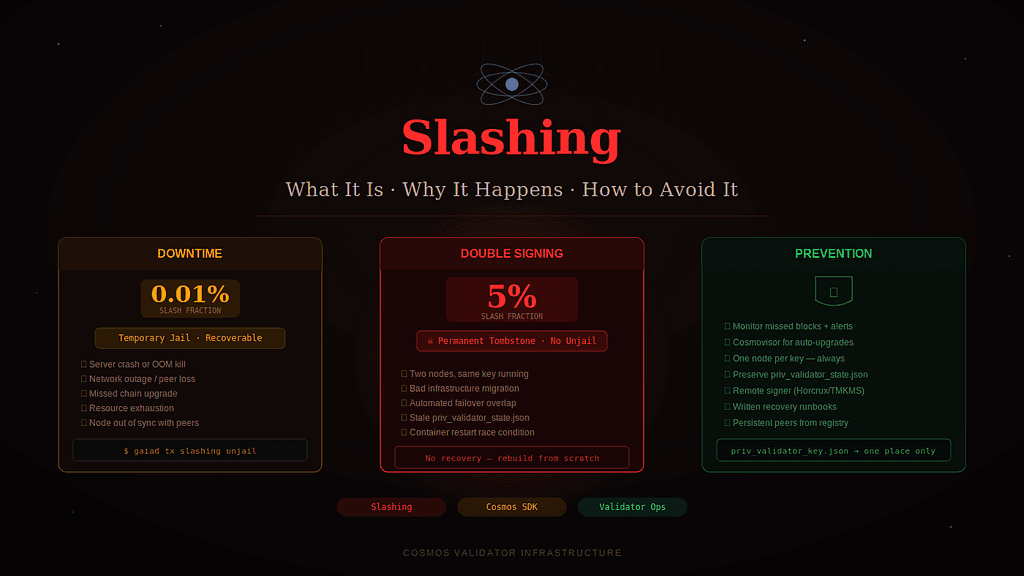
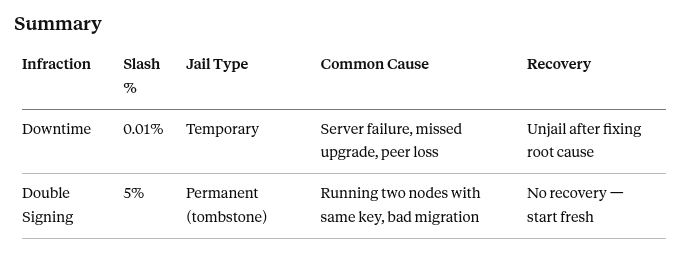
How it works: The Cosmos SDK tracks a rolling window of blocks (typically the last 10,000). If your validator misses more than a threshold percentage of signatures within that window (commonly 5% — meaning 500 out of 10,000 blocks), it gets jailed and slashed.
Typical parameters (vary by chain):
signed_blocks_window: 10,000 blocks
min_signed_per_window: 5% (must sign at least 9,500 of 10,000)
slash_fraction_downtime: 0.01% (0.0001)
downtime_jail_duration: 10 minutes
What happens:
- Validator is automatically jailed
- 0.01% of bonded stake is slashed
- Validator is removed from the active set
- After the jail duration, the operator must manually unjail with gaiad tx slashing unjail
The slash fraction for downtime is small — 0.01% is painful but survivable. The real cost is the reputational damage, delegator churn, and the missed block rewards during the downtime period.
Important nuance: Your validator can be jailed even if your node is technically running. If your node is out of sync, unable to reach peers, or stuck behind on consensus, it will miss signatures even though the process is alive.
2. Double Signing (Equivocation)
What it is: Your validator signs two different blocks at the same height and round. This is the consensus equivalent of voting twice.
How it works: CometBFT requires validators to sign exactly one block per height per round. If two valid signatures from your validator key are detected for the same height — even if you didn’t intend it — the protocol treats it as equivocation.
Typical parameters:
slash_fraction_doublesign: 5% (0.05)
doublesign_jail_duration: MaxInt64 (permanent — you cannot unjail)
What happens:
- 5% of all bonded stake is permanently slashed — yours and every delegator’s
- Validator is permanently jailed (tombstoned)
- The validator key is marked as tombstoned and can never be used again
- No unjail transaction exists for this state — it is terminal
A 5% slash on a validator with 1M ATOM bonded means 50,000 ATOM burned. Every delegator loses 5% of their stake instantly. This is a trust-destroying, delegation-destroying event.
The terrifying part: Double signing almost never happens because a validator operator is malicious. It almost always happens because they were trying to do the right thing — recovering from downtime, migrating infrastructure, or running a backup node.
Why Slashing Happens: The Real-World Causes
Downtime Causes
1. Server failure The most common cause. Hardware failure, OOM kills, kernel panics, disk full — anything that stops your gaiad process will start the clock on missed blocks.
2. Network issues Your node is running but isolated. ISP outage, firewall misconfiguration, or DDoS on your IP can cut you off from peers entirely. Your node keeps running but stops signing.
3. Missed chain upgrades Cosmos chains upgrade via governance. If you miss the upgrade height and don’t update your binary in time, your node halts while the rest of the chain moves forward. Every block after the halt is a missed signature.
4. Misconfigured peers Too few peers, bad peer list, or all peers dropping simultaneously. Your node loses sync and starts missing blocks even though the process is healthy.
5. Resource exhaustion CPU pegged at 100% during high-traffic periods, memory pressure causing swap thrashing, or disk I/O saturation. Your node is alive but can’t process blocks fast enough to keep up.
6. Consensus stuck Edge cases in CometBFT where your node gets stuck in a consensus round and stops progressing. Rare but happens, especially around upgrades or unusual network conditions.
Double Signing Causes
1. Running two nodes with the same key simultaneously The most common cause by far. An operator spins up a new server, copies their priv_validator_key.json, starts the new node — and forgets the old one is still running. Both nodes sign. Slash.
2. Infrastructure migration gone wrong Moving from server A to server B. Operator shuts down A, starts B, then realizes B isn’t synced yet and temporarily restarts A “just to be safe.” Both nodes are live during the overlap. Slash.
3. Automated failover without protection A monitoring script detects the primary is down and automatically starts the backup. Primary recovers on its own. Both nodes are now signing. Slash.
4. Snapshot restore with stale priv_validator_state.json The priv_validator_state.json file tracks the last signed height, round, and step. If you restore a snapshot and overwrite this file with a stale version, your node may re-sign blocks it already signed at those heights.
5. Containerized environments Docker or Kubernetes restarts a validator container without proper shutdown — the old container keeps running for a few seconds while the new one starts. Both sign simultaneously.
How to Avoid Downtime Slashing
Keep Your Node Healthy
Monitor your missed block count actively. Don’t wait for jailing — alert when your validator starts missing blocks, not after it has missed 500.
# Alert if missed blocks increases by more than 10 in 5 minutes
increase(cometbft_consensus_validator_missed_blocks[5m]) > 10
Set a peer count alert. Fewer than 5 peers is a warning sign. Fewer than 3 means you’re at risk of losing sync.
cometbft_p2p_peers < 5
Use persistent peers and a seed node list. Hardcode at least 5–10 reliable persistent peers from the chain registry. Don’t rely solely on address book discovery.
Monitor disk space aggressively. A full disk silently kills your node. Alert at 80%, act at 85%, panic at 90%.
Stay Current on Upgrades
Subscribe to the chain’s governance forum, Discord, and GitHub. Most chains announce upgrades weeks in advance. Set calendar reminders for upgrade heights.
Use cosmovisor to automate binary upgrades:
# cosmovisor watches for governance upgrades and swaps binaries automatically
# Place the new binary in:
~/.gaia/cosmovisor/upgrades/<upgrade-name>/bin/gaiad
cosmovisor doesn't eliminate the need for monitoring during upgrades, but it removes the manual step of being online at the exact upgrade height.
Build Operational Runbooks
Document exactly what you do when:
- Your node stops signing
- Your server becomes unreachable
- You need to migrate to new hardware
Having a written runbook means you make fewer panicked decisions at 3 AM when your validator is approaching the jail threshold.
How to Avoid Double Signing: The Cardinal Rules
Rule 1: Only One Node Signs at a Time — Ever
This cannot be overstated. There must never be two running instances of your validator with the same priv_validator_key.json simultaneously. Not for one minute. Not for one block.
Before starting a new validator instance, verify the old one is completely stopped:
# On the old server — confirm the process is dead
systemctl stop gaiad
systemctl status gaiad # must show "inactive (dead)"
ps aux | grep gaiad # must return nothing
# Only then start the new instance
Rule 2: Never Copy priv_validator_key.json Carelessly
Your priv_validator_key.json is the most sensitive file on your server. Every copy you make is a potential double-signing event waiting to happen.
Best practices:
- Keep it in exactly one place: your active validator’s ~/.gaia/config/ directory
- Never SCP it to a new server while the old node is running
- Treat it like a private key — because it is one
- Consider using a remote signer (Horcrux, Web3Signer) so the key never lives on the validator node at all
Rule 3: Preserve priv_validator_state.json During Migrations
This file tracks your last signed height. It’s your node’s protection against re-signing old blocks.
# When migrating to a new server:
# 1. Stop old node completely
systemctl stop gaiad
# 2. Copy BOTH key files to new server
scp ~/.gaia/config/priv_validator_key.json newserver:~/.gaia/config/
scp ~/.gaia/data/priv_validator_state.json newserver:~/.gaia/data/
# 3. Only then start new node
Never overwrite priv_validator_state.json with a stale copy from a snapshot. If the snapshot's state file is older than your actual last signed block, your node may re-sign those heights.
# When applying a snapshot, preserve your current state file:
cp ~/.gaia/data/priv_validator_state.json ~/priv_validator_state.json.bak
# Apply snapshot (this will overwrite it)
# Then restore your state file:
cp ~/priv_validator_state.json.bak ~/.gaia/data/priv_validator_state.json
Rule 4: Disable Automated Failover (or Use a Remote Signer)
Automated failover is dangerous without double-signing protection. A script that starts your backup node when the primary goes down can easily create a window where both are signing.
If you want high availability without double-signing risk, use a remote signer with HA support:
- Horcrux — threshold signing (2-of-3 or 3-of-5 signers). Your validator key is split across multiple signing nodes. Even if two nodes are running, signing requires a threshold — no single node can double sign.
- TMKMS — key management service that adds a signing layer between your node and your key. Supports hardware security modules (Ledger, YubiHSM).
These tools are the professional standard for serious validator operations.
Rule 5: Never Restore from Snapshot Without Reading the State File
Before restoring any snapshot, check what height your current priv_validator_state.json records:
cat ~/.gaia/data/priv_validator_state.json
{
"height": "15482300",
"round": 0,
"step": 3
}Your restored node must start from a height at or above this value. If the snapshot restores state at height 15,400,000 but your state file says you last signed at 15,482,300, your node will re-sign blocks 15,400,000 through 15,482,300 as it replays them — producing double-sign evidence.
Recovery: What to Do If You Get Jailed
For Downtime Jailing
- Fix the underlying cause first — don’t unjail into the same problem
- Ensure your node is fully synced (catching_up: false)
- Verify peer count is healthy (10+ peers recommended)
- Unjail:
gaiad tx slashing unjail \
--from <validator-wallet> \
--chain-id cosmoshub-4 \
--gas auto \
--gas-adjustment 1.5 \
--fees 5000uatom
- Monitor your signing rate for the next 30 minutes to confirm recovery
For Double Signing (Tombstoning)
There is no recovery from a tombstone. The validator key is permanently banned from the active set.
Your only path forward:
- Create a new validator with a fresh key
- Rebuild delegator trust from zero
- Communicate transparently with your delegators about what happened
This is why prevention is everything with double signing. There is no undo.
Slashing Best Practices Checklist
Infrastructure
- Monitoring with alerts on missed blocks, peer count, disk, CPU
- Cosmovisor configured for automated upgrades
- Persistent peers set from chain registry
- Disk alerts at 80% and 95%
- Node exporter + Prometheus + Grafana stack running
Key Management
- priv_validator_key.json exists in exactly one place
- priv_validator_state.json is preserved during any migration
- Remote signer (Horcrux or TMKMS) considered for production
- No automated failover without double-signing protection
Operational
- Written runbook for node recovery
- Chain upgrade calendar maintained
- Governance forum and Discord notifications enabled
- Snapshot restore procedure documented and tested
- Two-person sign-off process for infrastructure changes (for teams)
Downtime is an operational problem you solve with monitoring and runbooks. Double signing is an architectural problem you solve with key management discipline and remote signers.
Most validators who get slashed for double signing weren’t careless — they were trying to recover fast and made a decision under pressure that they couldn’t reverse. The best protection is a culture of deliberate, checklist-driven infrastructure changes, and a technical architecture that makes double signing physically impossible.
Slashing: What It Is, Why It Happens, and How to Avoid It was originally published in Vitwit on Medium, where people are continuing the conversation by highlighting and responding to this story.